Curious behavior when de-duplicating a collection in PowerShell
Aug 2, 2016This is a bug/curiosity in PowerShell that I stumbled upon a few years ago, but never wrote up. The behavior hasn’t changed significantly in the intervening verions, so now I’m finally getting around to a quick blog post.
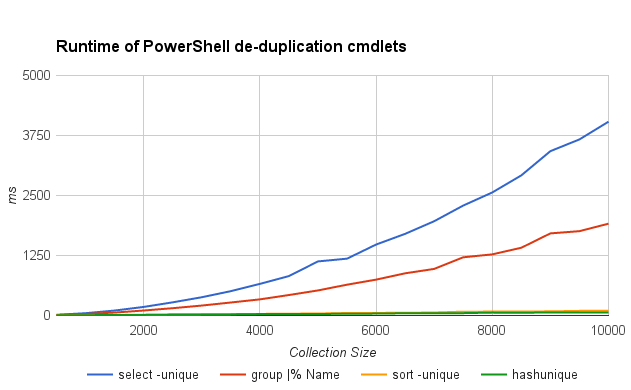
Here’s a chart detailing the runtime of 4 different PowerShell approaches to de-duplicate a collection - i.e. filter an input collection to just its unique elements. Code used for the benchmark can be found here.
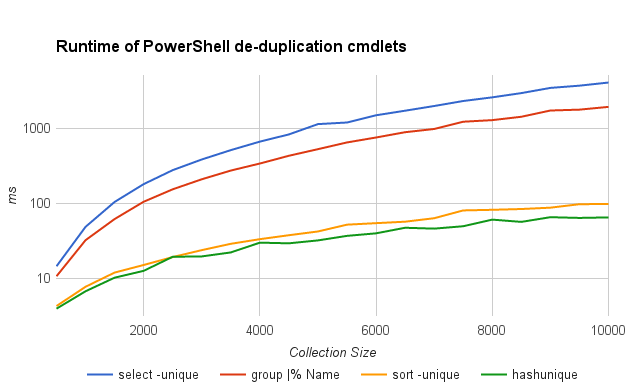
Same chart, with log scale so it’s a little easier to distinguish the trend lines:
The solutions being compared are:
$data | select -unique- Built-in, does nothing but de-duplicate the input collection.
$data | group |% Name$data | sort -unique- Built-in, sorts the input collection and additionally de-duplicates it.
$data | hashunique- Custom cmdlet using simple hashset-based approach. 12 lines, available alongside benchmark code.
I was surprised to see how poorly select -unique performs. It’s part of the core
PowerShell library (presumably authored by experts), implemented as compiled C# code
(not script), and its sole purpose is to solve this exact problem.
So why is it the slowest option?!
Specific questions I’m still wondering about -
Why do “select” and “group” have quadratic runtime?
Filtering out duplicates from a collection, or grouping together equivalent items,
can be done in
\(O(n)\)
time by utilizing a hash set or hash table, respectively.
The trendline above hints, and a quick ILSpy session confirms,
that
select and group are instead relying on an
\(O(n^2)\)
algorithm
that doesn’t use hashing at all.
My best guess is that somehow PowerShell’s object and equality system preclude efficient, reliable hashing for all scriptable objects, so they decide not to do it for any objects. Perhaps everything just relies on equality.
But this doesn’t quite hold up. Here’s a simple example where two items are considered
non-unique by select, sort, and group yet aren’t considered equal:
PS> 'dude' > sweet.txt
PS> $f1 = dir .\sweet.txt
PS> $f2 = dir .\sweet.txt
PS> ($f1, $f2 | select -Unique).Length
1
PS> ($f1, $f2 | sort -Unique).Length
1
PS> ($f1, $f2 | group).Length
1
PS> $f1 -eq $f2
False
Practically speaking, when I’m at the terminal and need to de-duplicate a
collection, 99% of the time it’s just going to be strings or numbers. It’s a shame
this core use case is left completely unoptimized. Going forward I will just keep
hashunique in my profile and use that.
Why is “group” faster than “select -unique”?
Setting aside asymtotic complexity, how can select -unique be slower by some constant
factor than piping together group |% Name? The latter has to carry around a ton of extra
data, and also incurs the cost of an additional pipeline command. This makes
no sense to me.